Implementation of the Language¶
Let’s recap how does the language looks like:
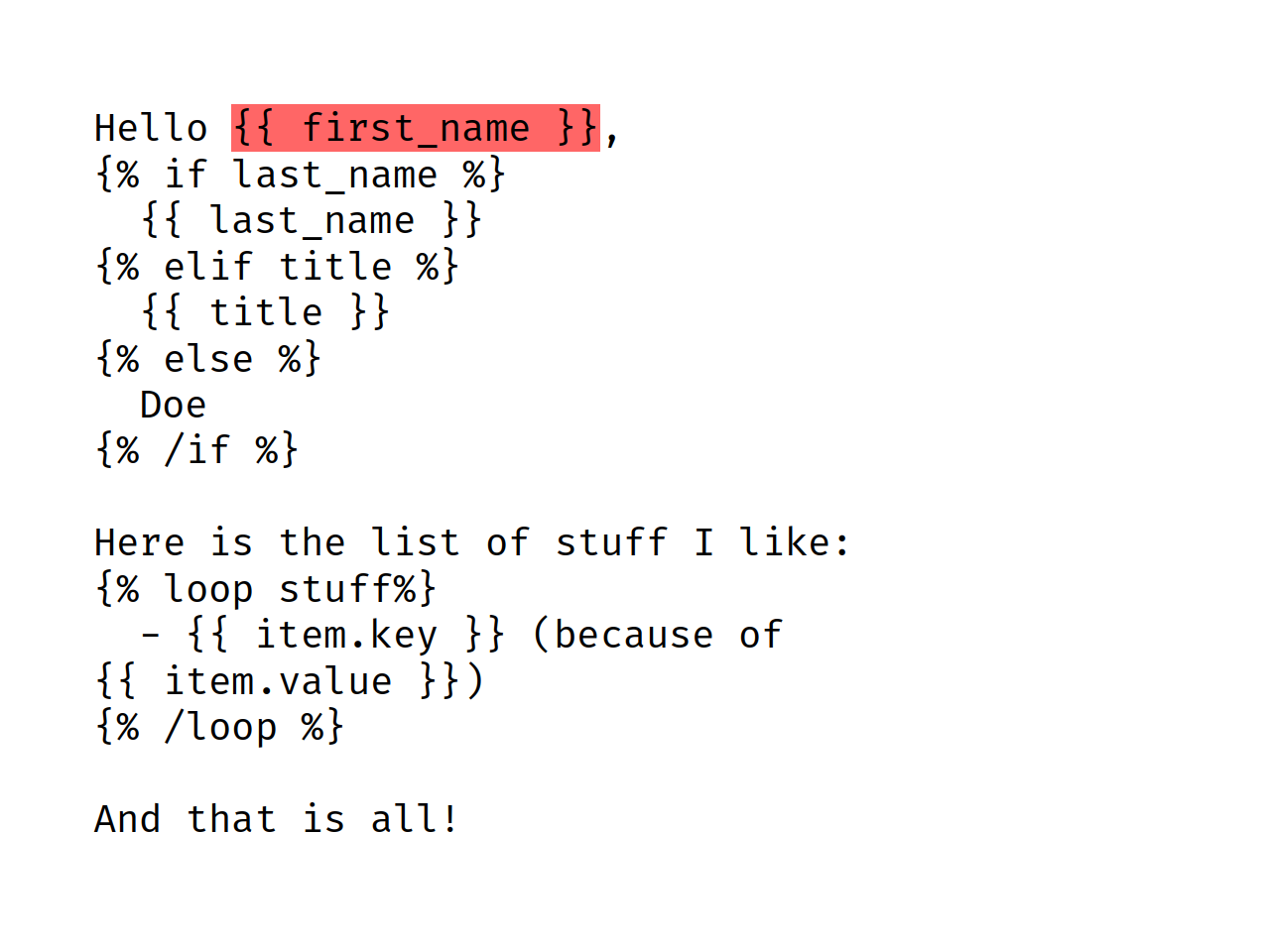
Hello {{ first_name }},
{% if last_name %}
{{ last_name }}
{% elif title %}
{{ title }}
{% else %}
Doe
{% /if %}!
Here is the list of stuff I like:
{% loop stuff %}
- {{ item.key }} (because of {{ item.value }})
{% /loop %}
The main goal of Curly is to make a little toy template language with a limited set of abilities just to show an idea of how to build such stuff. It has to be as simple as possible:
User who knows nothing about lexing and parsing, LALR, LR, LL and other stuff from compiler and language processing theory.
I, for example, have no big practical experience in implementation of such things (university maybe but not that much) but know how to work with regular expressions very well. For my point of view, this is a minimal prerequisite for understanding of Curly implementation.
No formal grammar. Formal grammar rocks but people from point 1 do not know them. My idea was to avoid formal grammar as much as possible: this could make parser complex. Anyway, we want to implement everything from scratch (except of regular expressions) and to understand how parser work, you do not need formal grammars to catch the ideas.
I want to give a tech talks on that and I am pretty limited in time of such talks. I want to cover all aspects and show all crucial parts in ~30 minutes. No way I would explain EBNFs and LR(0) stuff.
Seriously, all that are simply names. I want to show an idea. Title ideas after, but do not produce yet another monads.
So, let’s pretend that no theory is created and our compilers and interpreters were delivered by UFOs or found in Maya tombs. How would you implement such template language?
Text Interpretation¶
Let’s consider our templater as a black box. Input - the text, template.
Output - something which can render required text (insert stuff from
given context, loop where necessary, manage conditionals). Well, here
are several ways on how to do that but any way involves recognizing of
controlling patterns like interpretation of {{ tags }} and various
{% block constructions %}.
The most straightforward implementation are going layers: a product of bottom layer is an input of the top layer. And each layer goes in more concrete abstractions till we get something evaluable.
This implementation proposes 3 layers:
- Lexing
- Parsing
- Evaluation
Lexing¶
The main idea of the lexing is to split raw unstructured text into defined typed chunks, a parts. This separation is context free, does not imply any semantics analysis. It just splits.
Let’s check the text we are going to process again:

We have a print statements here, if and loops. So we have a mix of
template own statements and expressions along with literal text we need
to output as is. Curly interprets them as a tokens. Yes, whole blocks
like {{ first_name }}. Why does it do it in this way? Well, more
granular tokenization like {{ leads to more complex parser and I
cannot explain whole template engine in 30-40 minutes. Therefore we have
to go barbarian even if it could drive nuts someone.
Let’s consider literal token as a blue color; print statement as an orange one. Open block tag would be green and close - red. In that case, we could get the following picture.

This is a structure of out text: literal, print, if start block, literal (yes, whitespaces), print and so on. Our raw text can be split into a list of chunks (we can use words token stream to define that list).
Let’s split it. If you are hurry to implement regular expressions to parse such tokens you almost immediately face with problem that regular expression for literal text is quite hard to write correctly. You can do some tricks with ordering but I would suggest you to... refuse to implement regular expressions for literal text at all. This leads to the most simple lexer you can implement. But let’s get back to lexing (remember: we do not implement any expressions for literal text!)
How to extract {{ first_name }} from the text? {% function
expression %}? Well, let’s define expression and function
first. Function (if, loop etc) can use following regexp:
[a-zA-Z0-9_-]+. Expression may have spaces between words
and may have some escape symbols (if we want { to be the part
of expression, then we need to escape it with \: \{). So,
expression is (?:\\.|[^\{\}])+.
Nice, now let’s define our print statement. Print statement
is an {{ expression }} but we want to be liberal on
whitespaces near braces so {{\s*([a-zA-Z0-9_-]+)\s*}}.
Implementing regular expressions for all possible tokens,
we can construct big regular expression for tokenization:
(?P<print>{{\\s*([a-zA-Z0-9_-]+)\\s*}})|(?P<start_block>...)|(?P<end_block>...)...
Now, to do lexing, we must go through all text extracting one non-overlapping pattern match by another till we get all tokens.
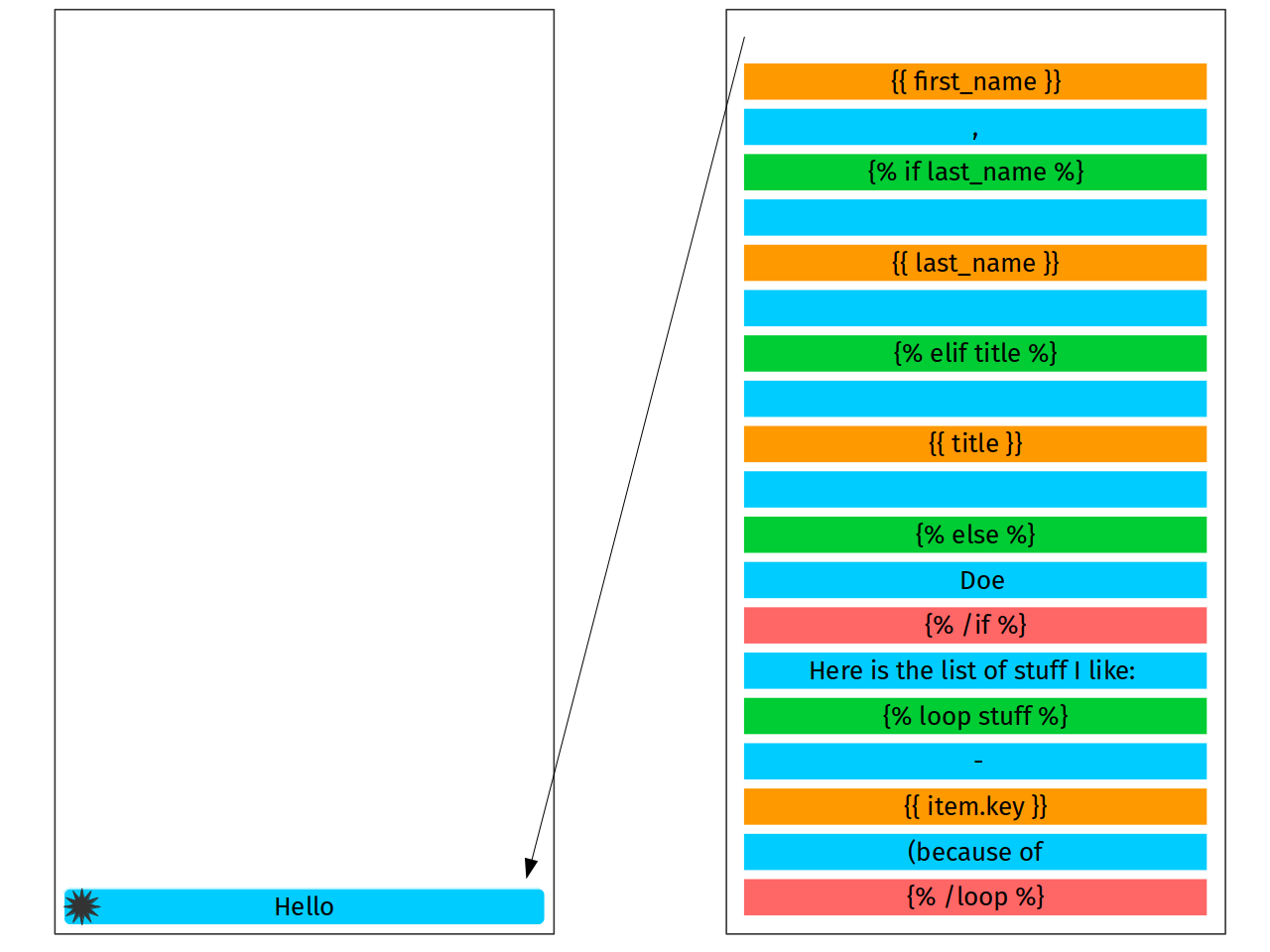
Nice, what about literal tokens? Let’s get back to out text. Let’s pretend that red box is a match we are working with.
From the start, we’ve jumped to {{ first_name }} skipping the
literal. To obtain literal, we need just to take text from position 0
till the match start: this would be out literal.
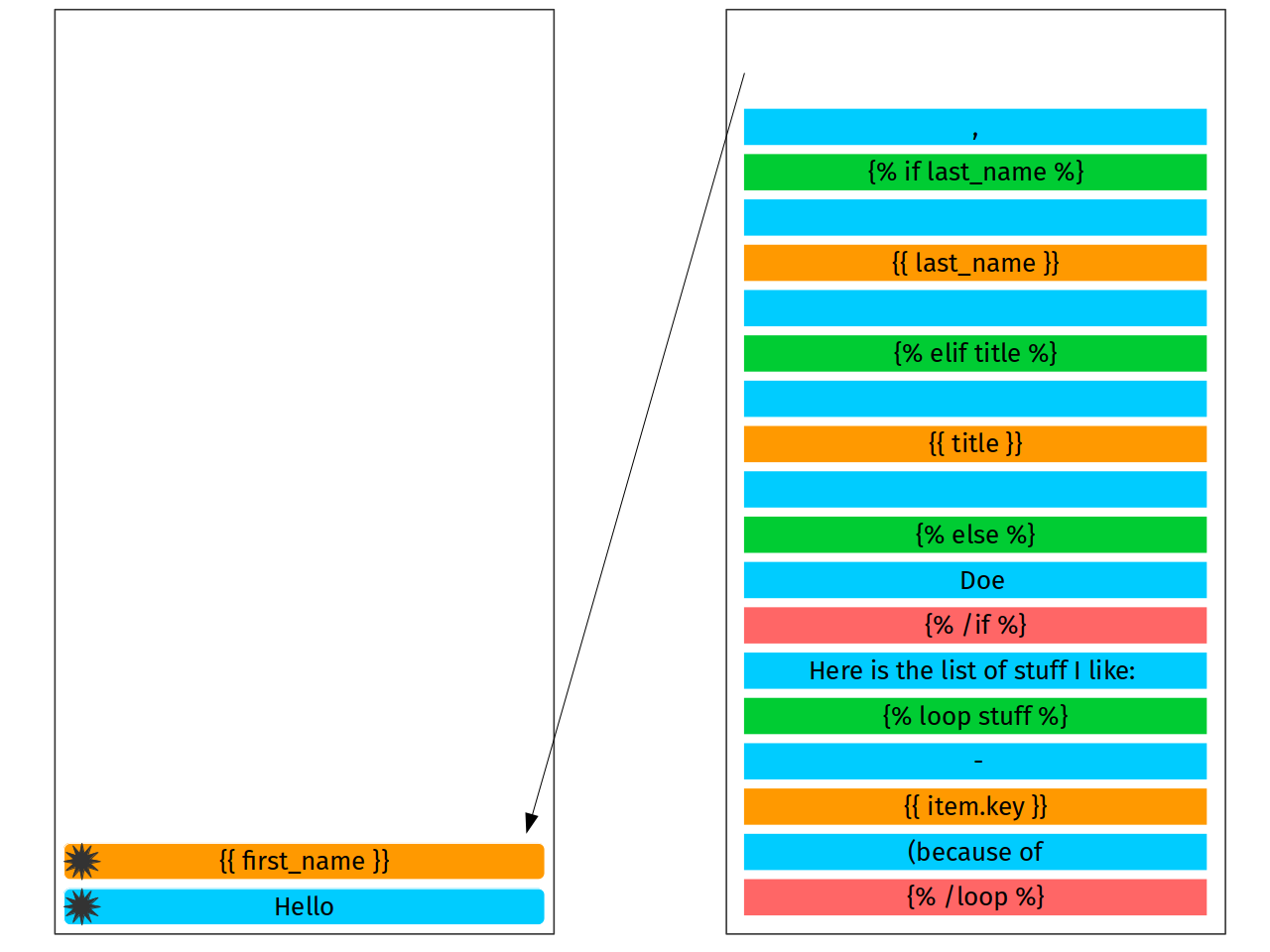
Let’s generalize this idea a little bit more. Considering
green box as a previous match and red box as a current
one, we can extract skipped literal text just as a
text[position_of_previous_match_end:position_of_current_match_start].
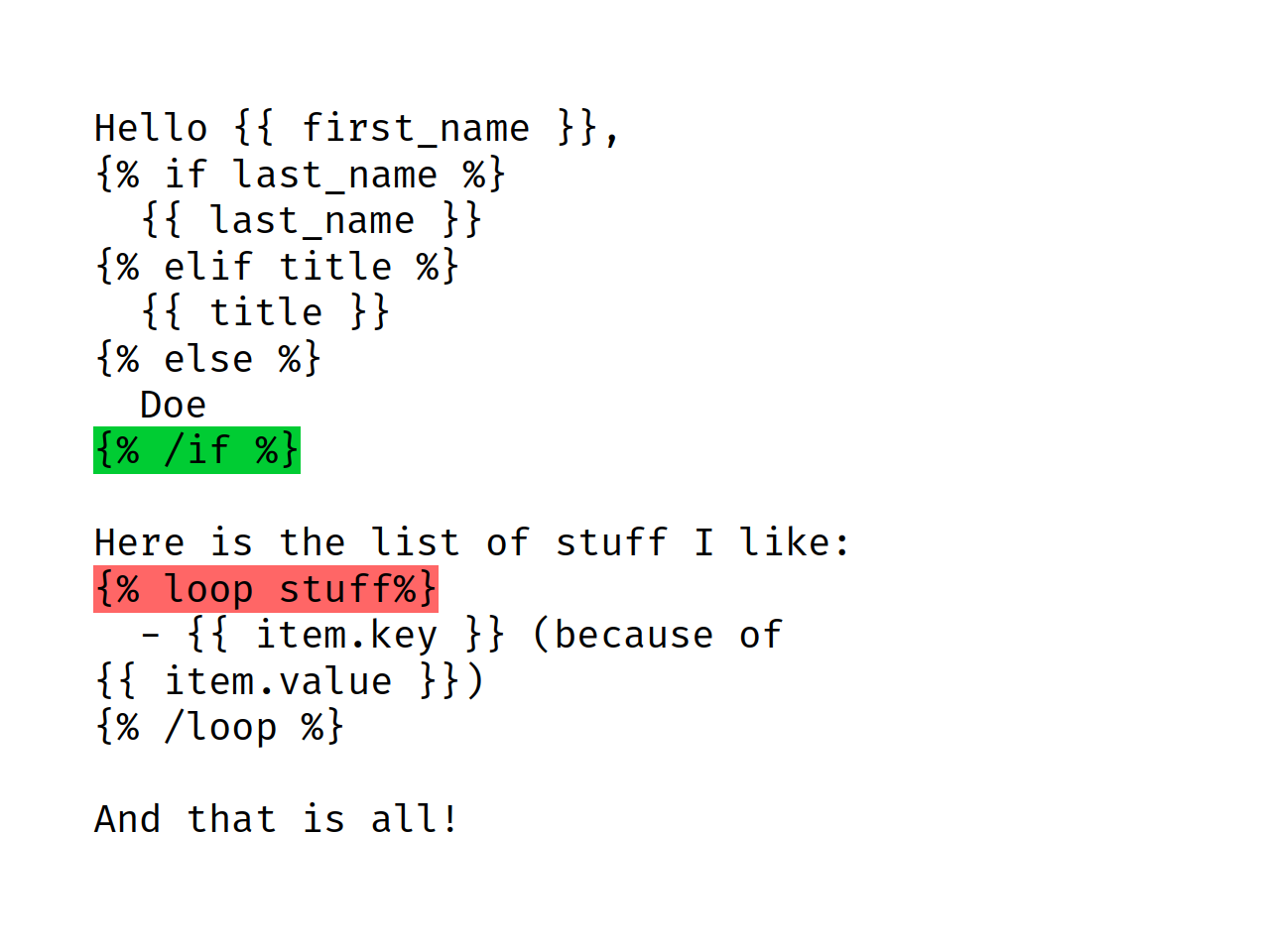
We’ve almost done. Last leftover is how to extract And that
is all! piece of text (matching has to be stopped and {%
/loop %}) block. This is simple: our leftover literal is
text[position_of_previous_match_end:end_of_the_text].
After that procedure, we will get following stream of tokens:

Note
To save a screen space, token stream is represented as a stack. Start is on the top of the stack, finish - at the bottom.
Parsing¶
After we’ve got token stream from Lexing, it is a time to do parsing. The main idea of the parsing is to get AST tree from the token stream. So, convert a list into the tree. Yes, before the AST tree we can have a parse tree but in our case it is almost indistinguishable from AST one.
To do that, we are going to use stack. From the left side is the stack of the parsed, from the right - incoming token stream. This token stream is present as stack also (elements are taken from the top) just to fit it on the screen. Also, some tokens were reduced but hopefully, it won’t hide the picture.

The main idea of parsing is simple: we are taking token from the incoming stream, look on it and decide what to do with stack. For example, we can rewrite a part of the stack. Or add new node on the top.
Right now we want to take first token from the stream. This is a literal
token Hello. This literal does not require any additional configuration
or processing therefore we can add literal node to the stack.
Note
Please pay attention to black start mark. All nodes in parser stack are marked as done and not done. Black star means that node is done. Done means that no additional actions on that node should be performed, it is ready for AST tree as is.
The next token is print {{ first_name }}. Again, corresponding node
is self sufficient: no children, responsible only for context later.
Next node is literal. The same story again.
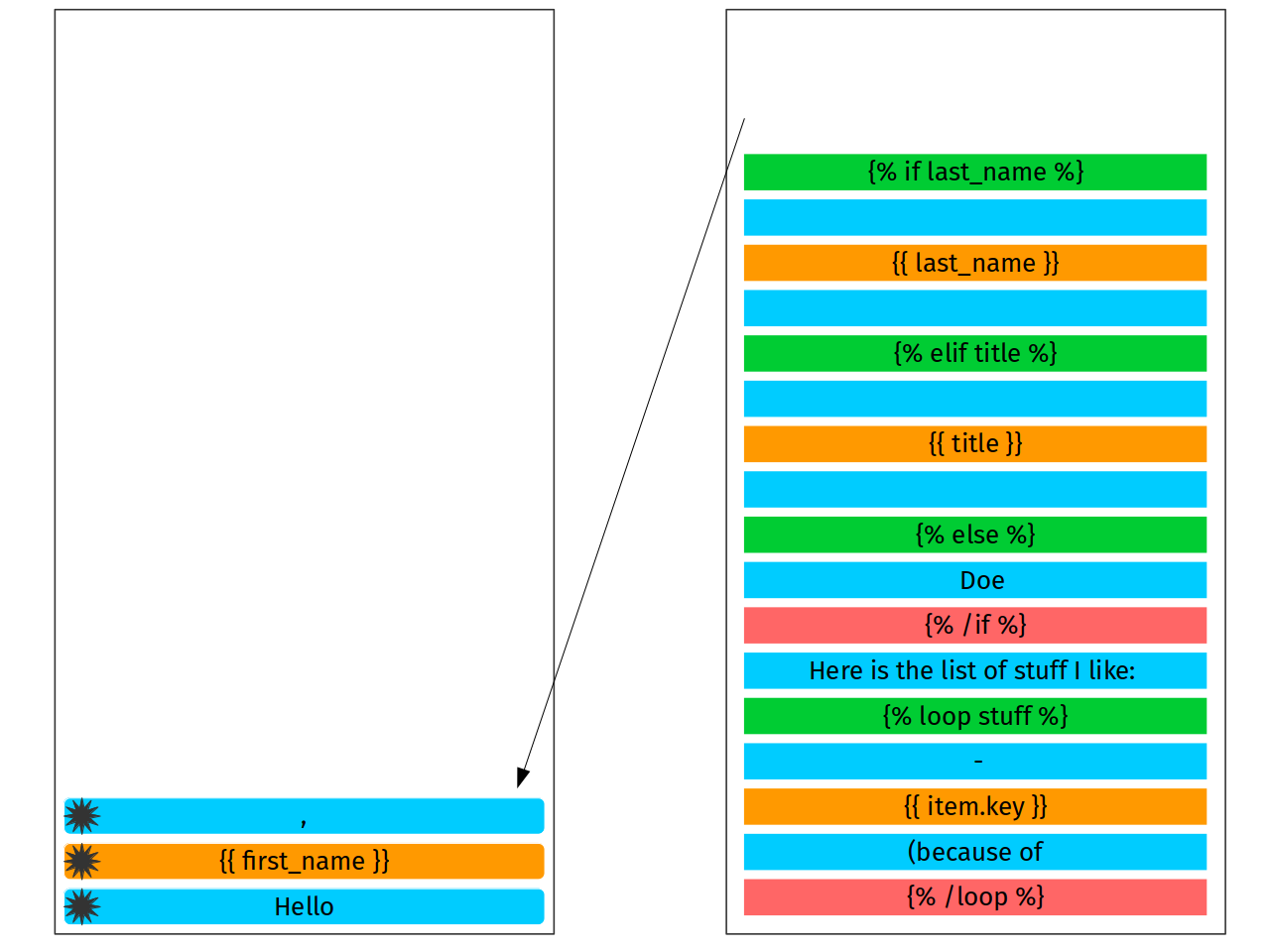
Next node is start block tag for conditional. And here is party begins.
Conditionals are complicated and their blocks have contents. Content is
rendered if expression is evaluated to true. So we cannot add this
node as done: the contents are upcoming and moreover, we cannot even
suggest how will this condition looks like: will it be a single if? Or a
number of if and elifs?
And what is elif? The most simple thing we can imagine is to present a single conditional block with a list of if and else statements. For example, we might have following syntax
{% conditional %}
{% if last_name %}
{{ last_name }}
{% /if %}
{% if title %}
{{ title }}
{% /if %}
{% else %}
Doe
{% /else %}
{% /conditional %}
Let’s assume that we’ve got such syntax implicitly. For that we need to add one conditional block (purple color) and out if block after on the top of the stack. Of course, they would be unfinished, without black star.
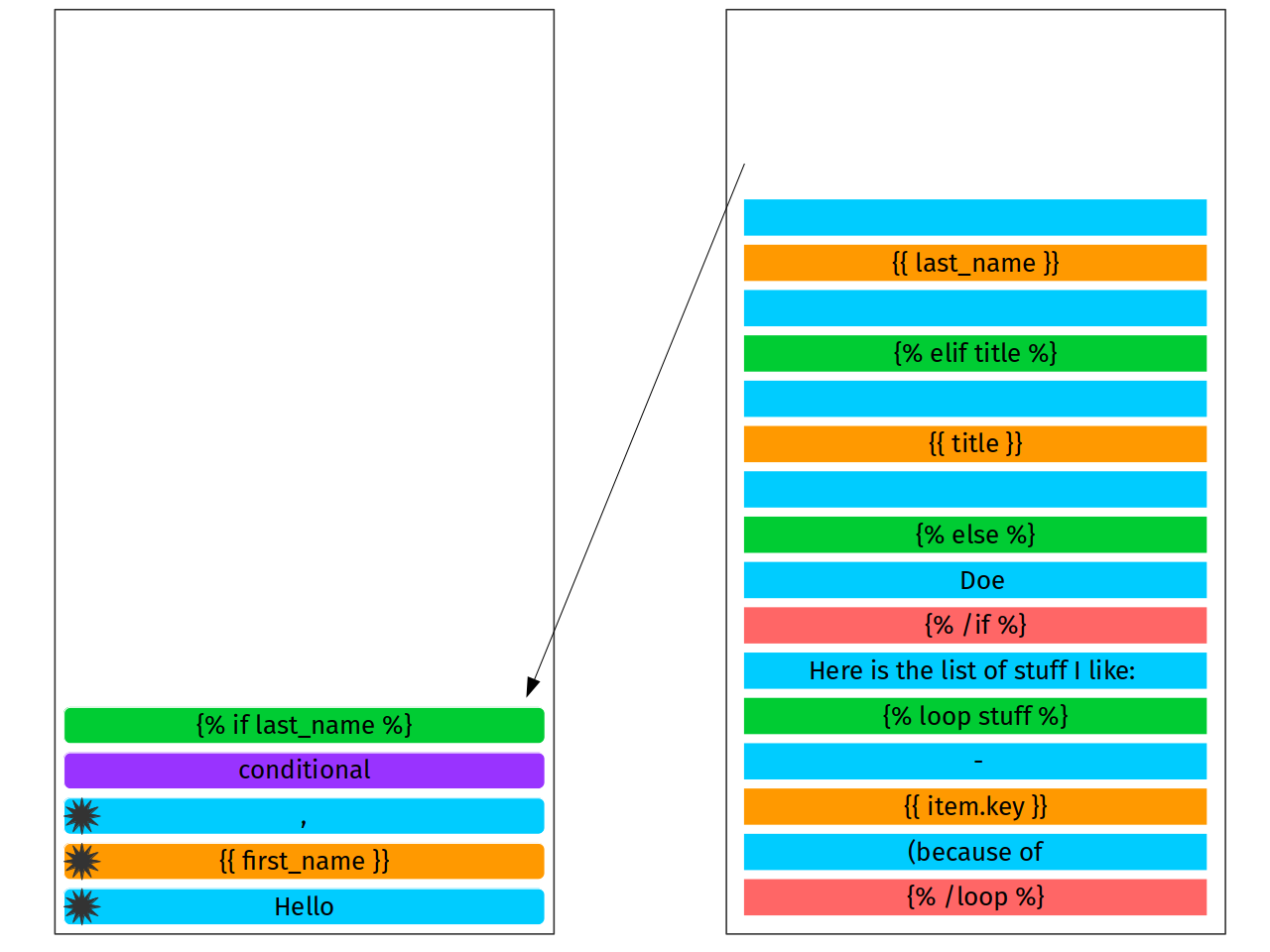
Important
Please pay attention that conditional and first if have no black star marks. This is not a misprint (mispicture?): seriously, block tags have a content so we are not finished with them yet, they are not ready to be rendered.
The next 3 nodes are breeze: literal, print and literal. They are ready to be put on the stack and no additional processing for any is required.
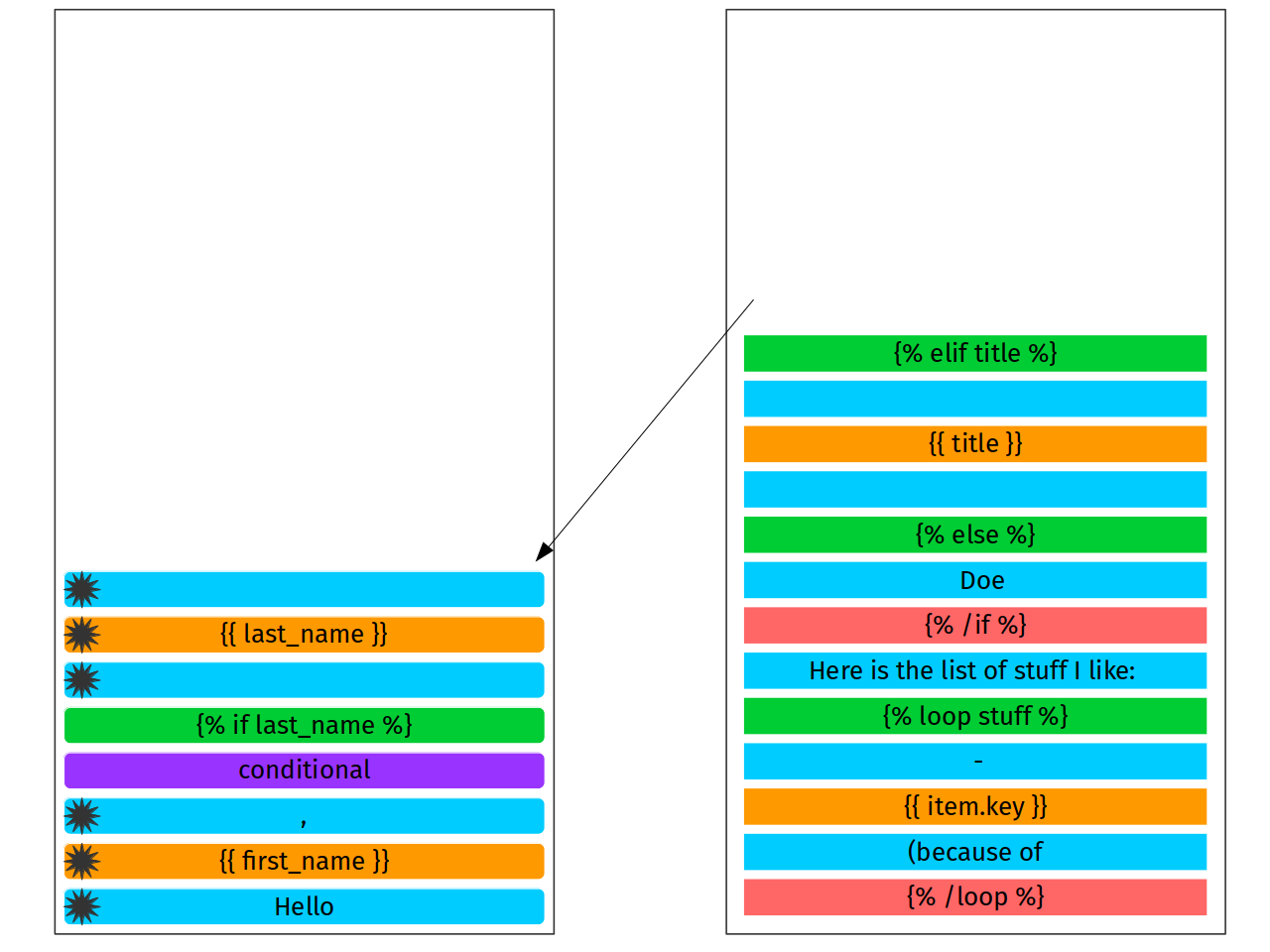
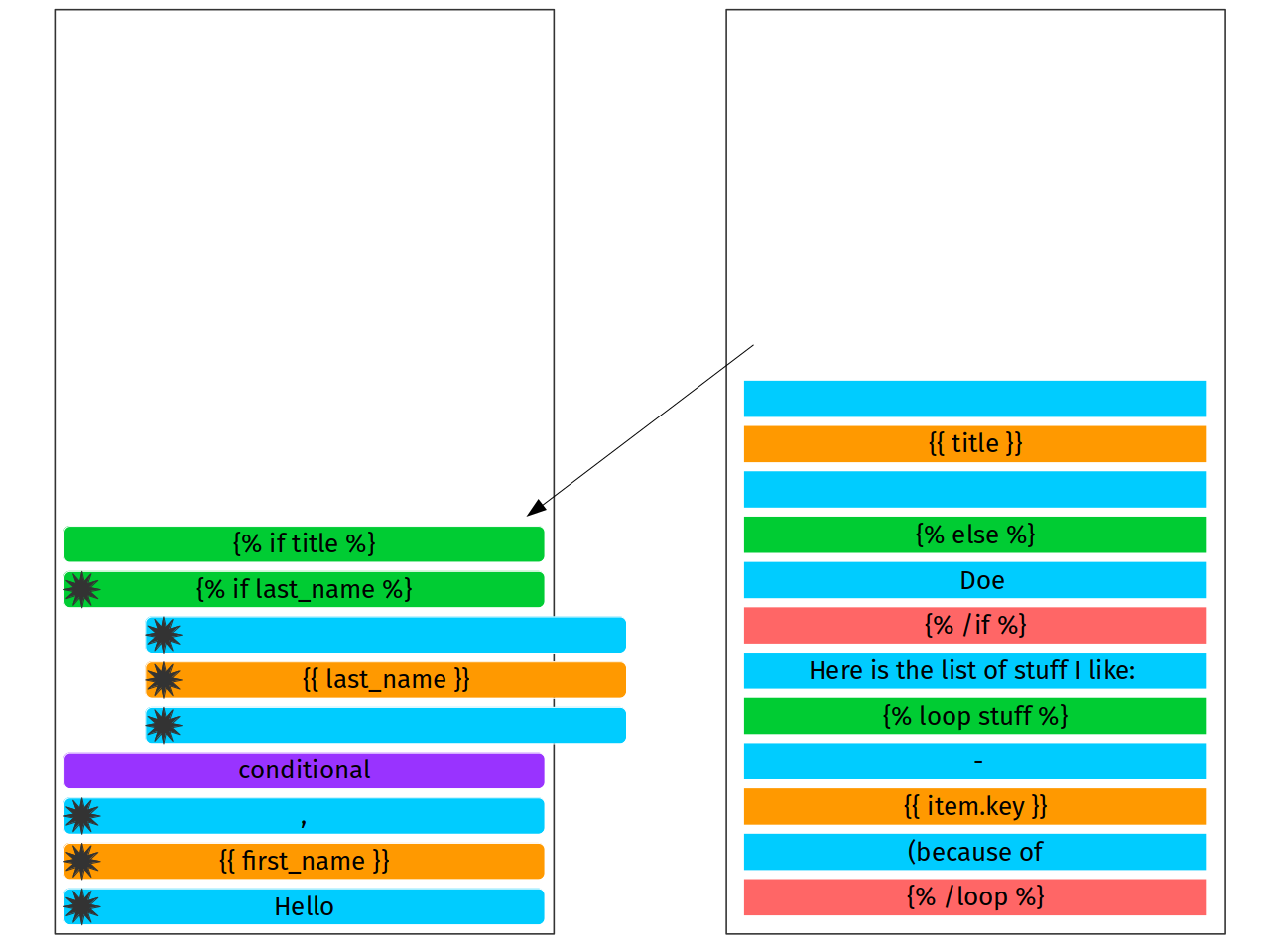
And now interesting: next node is {% elif title %}. What does it
mean for us? It actualy means, that scope of {% if last_name %} has
been completed, finished, closed. Nothing to do there, no tokens will
be appended. Now it is a time of reduce phase.
Reduce phase means that we are popping tokens out of stack until first
unfinished is found. And this first unfinished we meet is our token
which has to be completed. If we’ve made no mistake in implementation,
this would be the truth. Otherwise, we have a syntax error (e.g {%
if something %}{% /loop %}). So, we are going to pop last 3 tokens
and connect them as a subnodes of first unfinished tag we meet, {% if
last_name %}
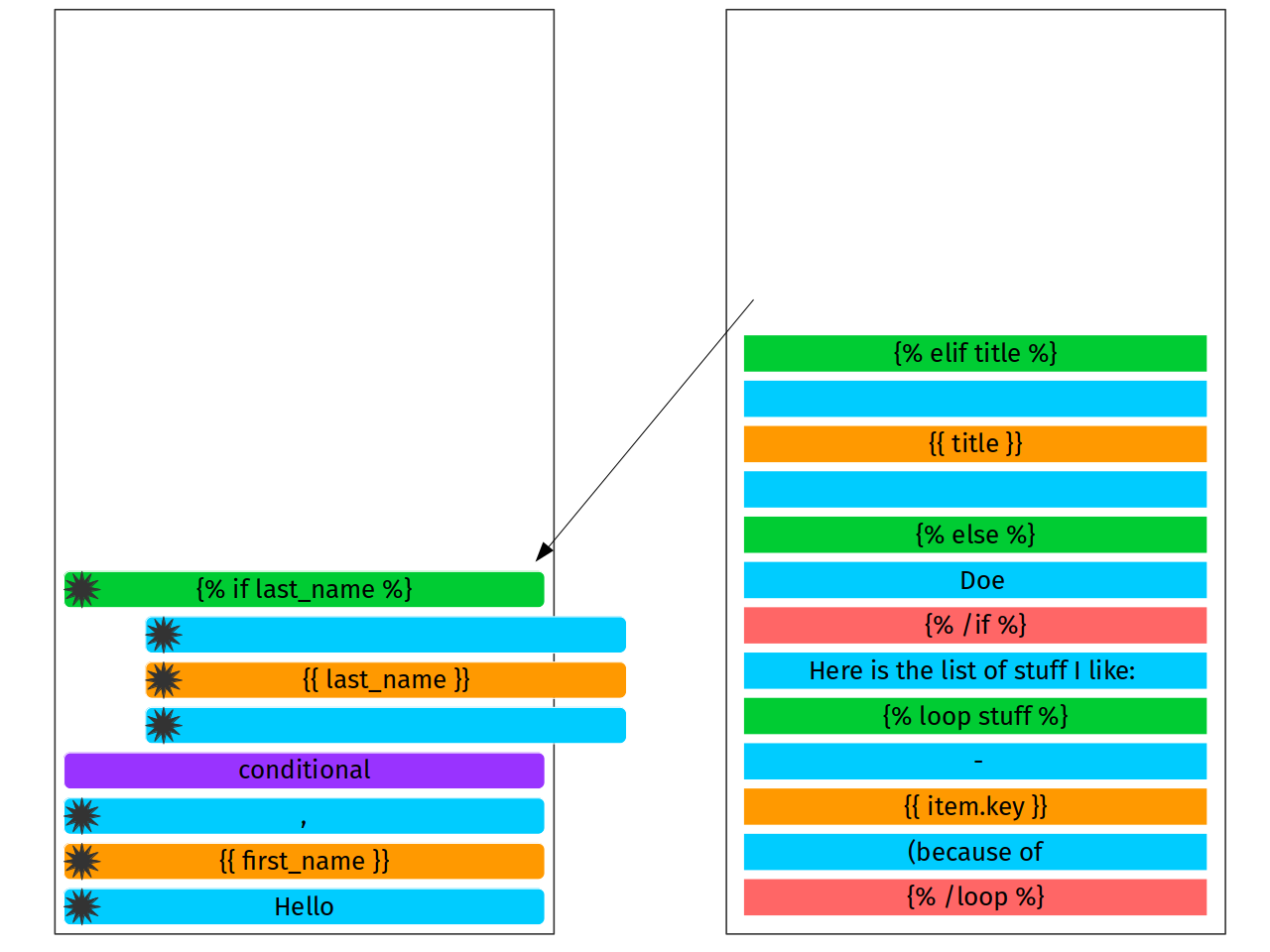
Reduce phase is over. Now we can add new if to the stack. This will
be the {% elif title %} which would be yet another if node: {%
if title %}.
Applying the same logic till {% /if %} we are getting following state:
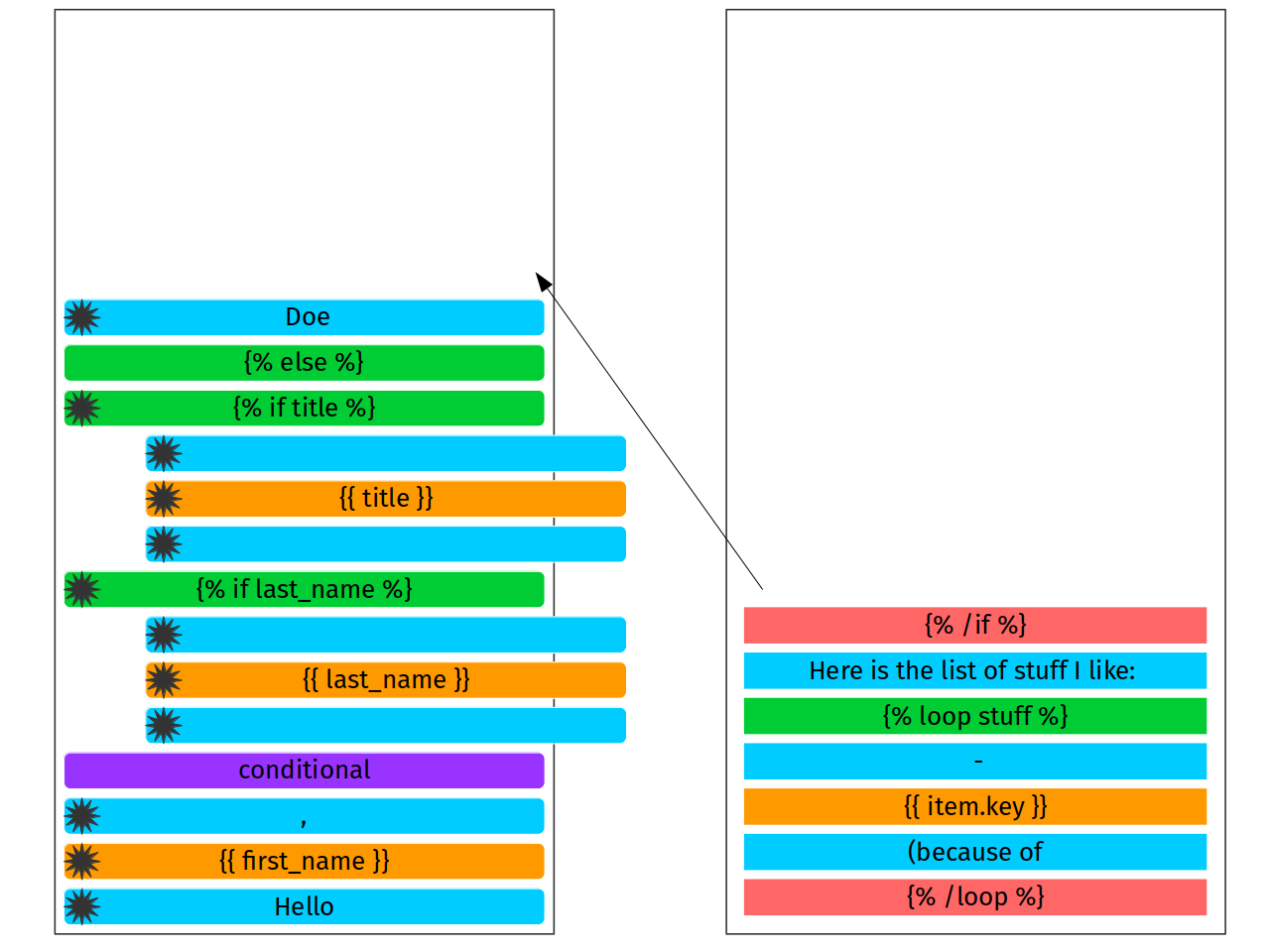
Okay, {% /if %} basically means that conditional is closed. All ifs,
elifs and elses have to be closed. This requires 2 stack rewinds.
First stack rewind is going to finish {% else %} node.
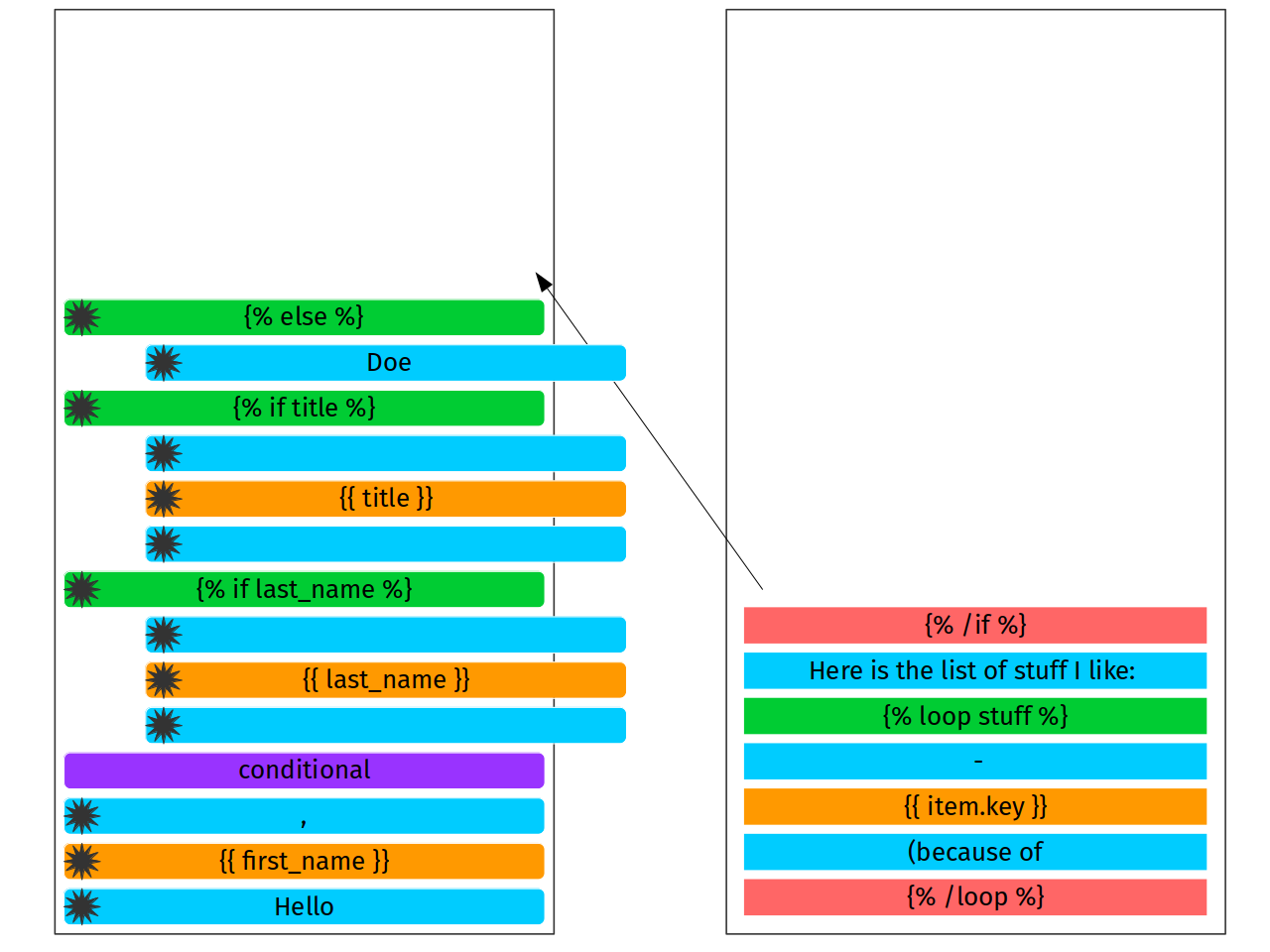
And the second rewind has to close conditional. Why? Because {%
/if %} closes whole condition.
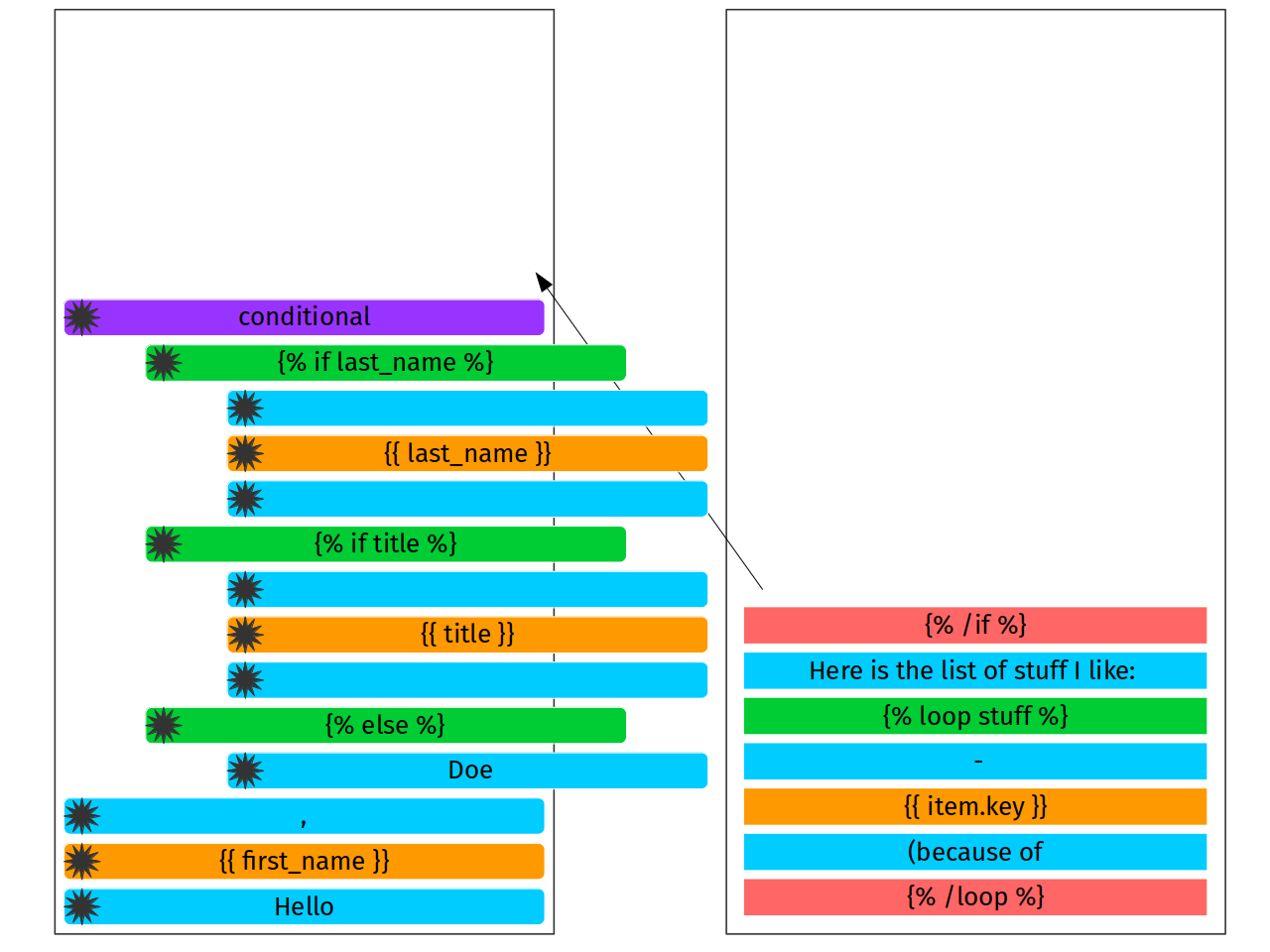
The funny thing is: we do not need conditional anymore. We can do
yet another reduce phase, popping it out, making a linked list from its
contents and popping first if statement (the head of the linked list to
the top of the stack).
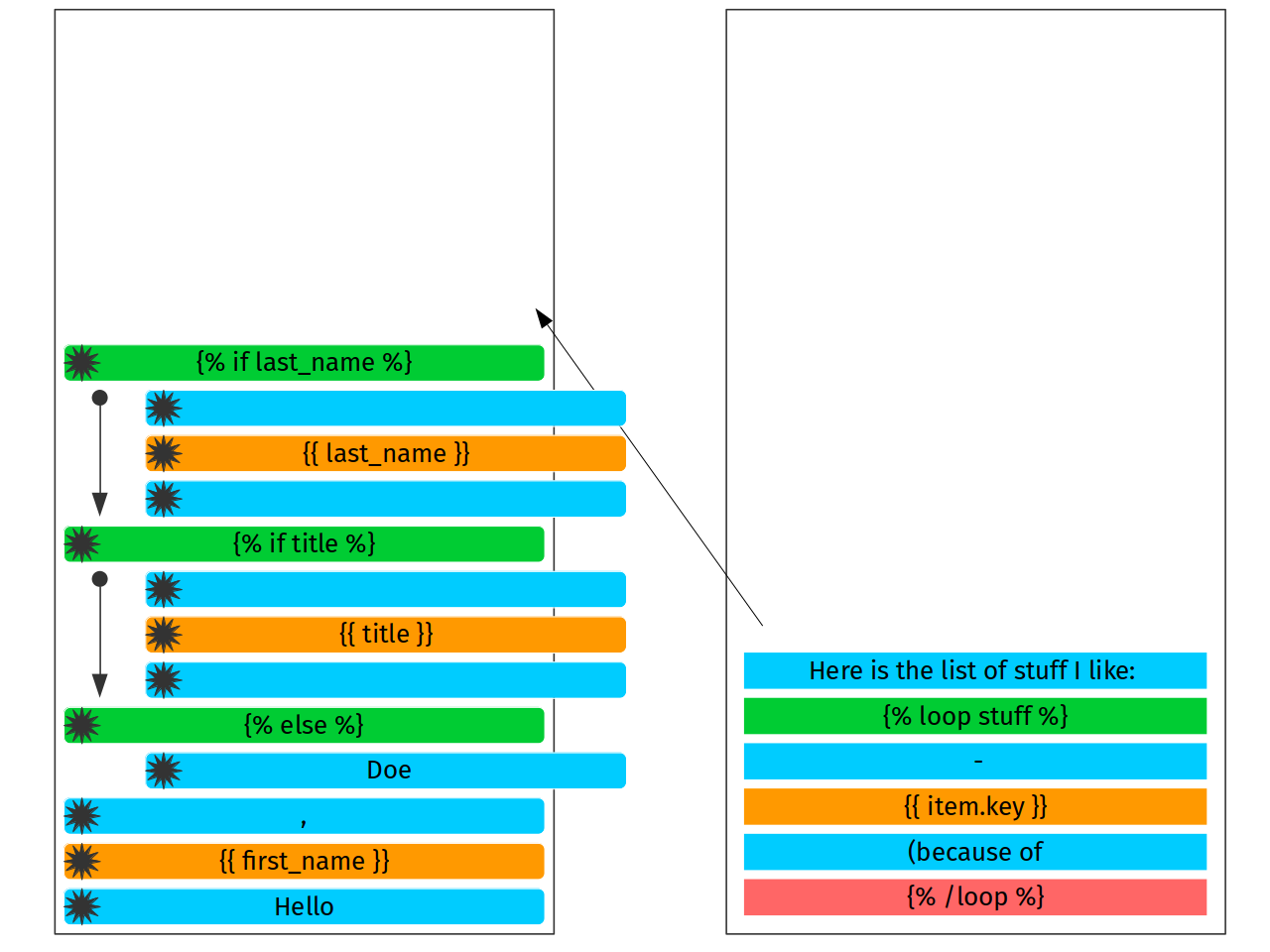
Put yet another literal token as a literl node on the top of the stack.
The next one is loop. Loop is similar to conditional but it does not
have any substuff like elif or else. Therefore we can just pop it as
unfinished on the top of the stack, fill it with contents and reduce on
{% /loop %}.

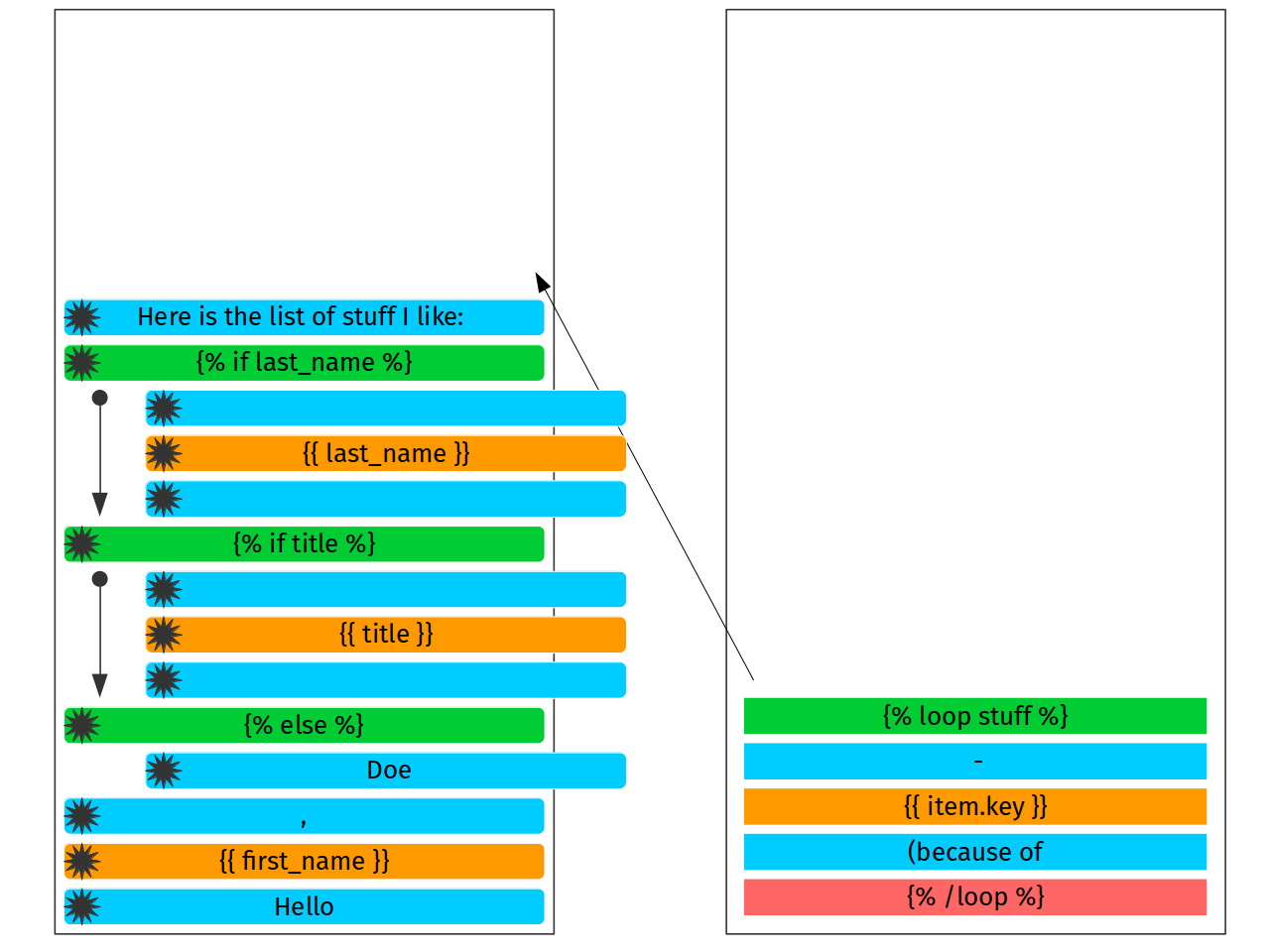
Token stream is exhausted, we need to do the last step: take all contents of stack and add it as subnodes to root node. Let’s make another picture in more familiar way:
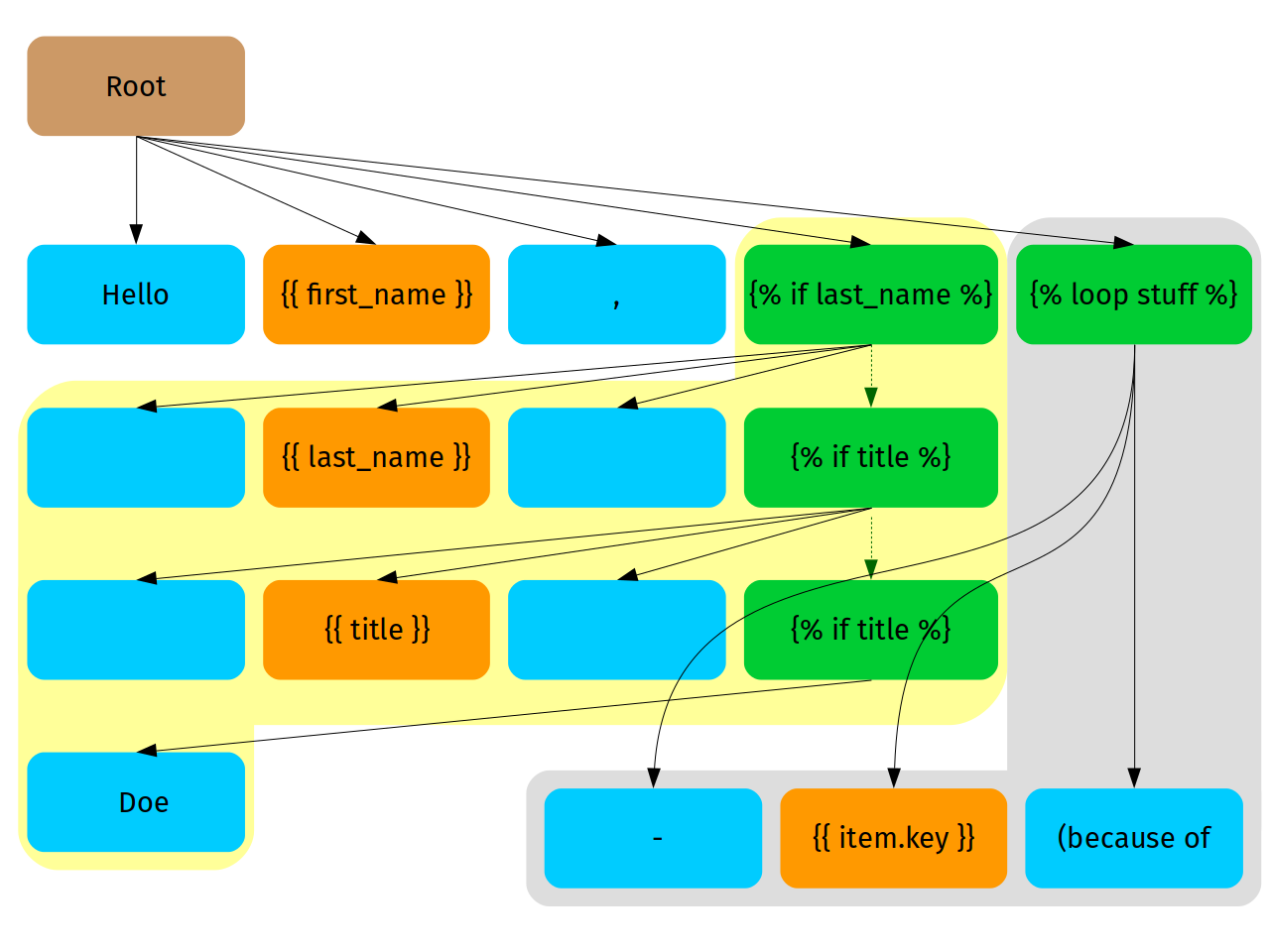
Please welcome, AST tree of out template.
Evaluation¶
To evaluate the tree, we have to make pre-order tree traversal. Each node should emit some text. If node has subnodes, then text it emits depends on evaluation of these subnodes. If you think about recursion here, yes, there is recursion.
Let’s explain evaluation with example. Consider template from the top of the page. We want to render following context:
{
"first_name": "Sergey",
"last_name": "",
"title": "Mr",
"stuff": {
"coffee": "taste",
"programming": "nerd heaven",
"music": "music"
}
}
Let’s traverse our tree step by step. First, root node. It has no its own content, text it emits is simply concatenation of texts from its subnodes.
Evaluate “Hello, ”: Hello,
Evaluate {{ first_name }}: Sergey
Hello, + Sergey = Hello, Sergey.
If evaluation is slightly different. Please be noticed that there is a
list of else nodes: nodes which should be evaluated if expression of the
node is not ok. Evaluate {% if last_name%} === if "". Actually,
this is false. Empty string is falsy. So we need a level deeper by
elsenode reference, Eto {% if title %}. This evaluates to True
({% if "Mr" %}). So we need to render subnodes. This evaluation is
" " + "Mr" + "" == " Mr". So, rendered content of if node is ” Mr”.
So, at this point, we have Hello, Sergey + ” Mr” == Hello, Sergey
Mr.
Loop just going through the iterable, injecting item into the
context. Results of iterations are concatenated. So, it is - coffee
(because of - programing (because of - music (because of.
And the resulting rendered template of the text on the top would be:
Hello Sergey,
Mr
Here is the list of stuff I like:
- coffee (because of taste)
- programming (because of nerd heaven)
- music (because of music)
And that is all!
And that is all!